
技术进步带来的好处似乎无穷无尽。我们可以通过手机查看家中的安全状况,接收无人机送货上门的杂货,甚至驾驶可以为我们并排停车的汽车。我们的电视机也变得同样先进,在不断增长的平台和频道中提供看似无穷无尽的内容选择。然而,尽管智能电视在未来几年将打开许多大门,但它们本身并不能让媒体行业准确了解谁在使用智能电视。
智能电视已经占据了当地大卖场的电视货架。如今,你很难在商店里找到一台不支持互联网的电视机。就像所有联网设备一样,智能电视使用户生成的数据日益激增:自动内容识别(ACR)数据是原始设备制造商用来捕捉智能电视调谐的技术。这些数据集与详细描述具有代表性的个人行为的信息相结合,极大地推动了受众测量科学的发展。
Given the wide adoption of smart TVs and the data they produce, it’s not surprising that an array of companies are looking to ACR data as a way to measure audiences. From a sheer scale perspective, the opportunity is very appealing. Yet as lucrative a data source as ACR is, it isn’t sufficient by itself to measure audiences, simply because it lacks the most important aspect there is in audience measurement: people. In addition to not being representative—or even aware if someone is actually watching what’s on the screen—ACR data has a critical validation flaw: It requires the device manufacturer to match the image on the screen with a reference image in order to determine what content is being displayed. So, the best way to unlock the true potential of ACR data is to calibrate it with data that reflects true person-level viewing behavior.
在按设计工作时,ACR 技术会监控投射到电视玻璃上的图像,并利用这些图像来推断正在显示的内容。ACR 提供的图像在很多方面就像内容的指纹。但在收集 "指纹 "后,该技术需要确定图像出现在哪个网络或平台上,以及出现的时间。为了进行判断,该技术需要将屏幕上的图像与制造商维护的参考库中的图像进行匹配。
当技术尝试进行匹配时,有三种可能的结果:
- 该图像与参考文献库中的一个条目相匹配
- 图像与参考资料库中的多个条目相匹配
- 参考资料库中没有匹配的图像
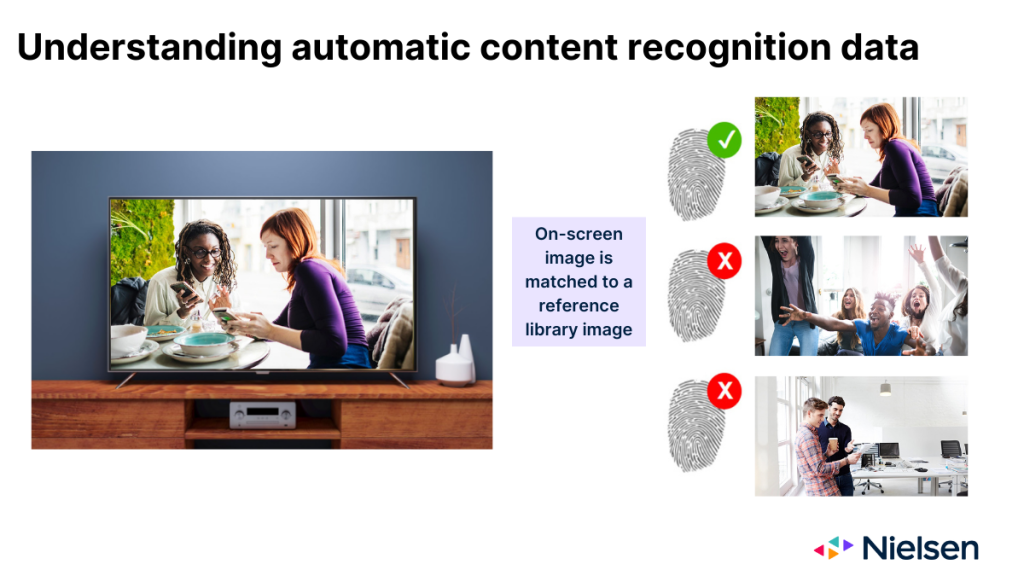
对所有相关方而言,第一种结果是最理想的情况。第二种情况就不那么理想了,它存在一定程度的错误记分风险,原因很简单,因为多场比赛有多种原因(如跨网播出、重复播出、同步播出)。在第三种情况下,没有人获得记分,这显然是最不理想的情况。造成这种结果的最常见原因是,内容在原始设备制造商没有监控的网络上播出。
即使图像匹配是一种可行的独立测量解决方案,也不可能将其作为一种可行的解决方案加以利用。可以想象,要维护一个包含电视上每一个事件的每一帧画面的资料库,所需的成本并不低。这也是一项将永久呈指数增长的任务。图像也没有标准的保存期限。
那么,我们如何知道 ACR 技术能够进行正确的匹配呢?如果没有能够填补空白的机制,我们就不知道。这就是尼尔森投资水印的原因,水印的确定性远高于签名,同时尼尔森还为每个测量数据源提供签名备份。这提供了所有内容的代表性,填补了与大数据本身相关的空白。填补了这些空白后,来自 ACR 等来源的大数据就能在日益细分的媒体环境中提供规模优势。当我们使用加权控制将大数据与个人层面的收视数据进行校准时,我们就能看到原本空白的比较点。
In a recent study, Nielsen looked to understand the degree to which these reference library gaps affect ACR tuning logs—the basis for ACR-based measurement. In a September 2021 common homes analysis, we analyzed data from our two ACR provider partners to understand where reference library gaps might factor into measurement. In our study, we looked at both the concentration of viewing sources and the viewed minutes from the available sources.
在所有收视来源中,我们发现 ACR 提供商合作伙伴仅监控了 31% 的可用电台。这意味着他们的参考库中没有保存 69% 的电台数据。当我们查看观看的分钟数时,我们发现 23% 的分钟数来自未受监控的电视台。这意味着,仅利用 ACR 数据进行测量的公司会少计 23% 的家庭级印象。
尽管 ACR 数据本身存在局限性,但我们深知其作为额外覆盖来源所提供的规模和覆盖范围的机会--类似于来自机顶盒的返回路径数据 (RPD),我们的大数据战略也将其与面板数据进行校准,以解决类似的局限性。通过将大数据集与我们的收视数据(可提供具有代表性的全美测量数据)相整合,我们能够大幅增加样本量,同时应用严格的数据科学方法来填补空白,确保公平地代表所有网络和平台上的全美受众。
A version of this article originally appeared on AdExchanger.



