
Die Vorteile der fortschreitenden Technologie sind scheinbar endlos. Wir können die Sicherheit unserer Häuser von unseren Telefonen aus überprüfen, Lebensmittellieferungen per Drohne empfangen und sogar Autos fahren, die für uns parallel einparken können. Auch unsere Fernsehgeräte werden immer fortschrittlicher und bieten eine scheinbar unendliche Auswahl an Inhalten über eine ständig wachsende Landschaft von Plattformen und Kanälen. Doch trotz der vielen Türen, die Smart-TVs in den kommenden Jahren öffnen werden, werden sie allein nicht in der Lage sein, der Medienbranche einen genauen Überblick darüber zu geben, wer sie nutzt.
Intelligente Fernsehgeräte haben den TV-Gang bei Ihrem örtlichen Großhändler erobert. Sie werden heute kaum noch einen Fernseher in einem Geschäft finden, der nicht internetfähig ist. Und wie alle vernetzten Geräte tragen auch Smart-TVs zu einer zunehmenden Vermehrung der vom Benutzer erzeugten Daten bei: ACR-Daten (Automatic Content Recognition) sind die Technologie, die OEMs verwenden, um die Einstellungen von Smart-TVs zu erfassen. In Kombination mit Informationen, die das repräsentative Verhalten auf Personenebene beschreiben, bringen diese Datensätze die Wissenschaft der Publikumsmessung erheblich voran.
Given the wide adoption of smart TVs and the data they produce, it’s not surprising that an array of companies are looking to ACR data as a way to measure audiences. From a sheer scale perspective, the opportunity is very appealing. Yet as lucrative a data source as ACR is, it isn’t sufficient by itself to measure audiences, simply because it lacks the most important aspect there is in audience measurement: people. In addition to not being representative—or even aware if someone is actually watching what’s on the screen—ACR data has a critical validation flaw: It requires the device manufacturer to match the image on the screen with a reference image in order to determine what content is being displayed. So, the best way to unlock the true potential of ACR data is to calibrate it with data that reflects true person-level viewing behavior.
Wenn sie wie vorgesehen funktioniert, überwacht die ACR-Technologie die Bilder, die auf das Fernsehglas projiziert werden, und nutzt diese Bilder, um daraus zu schließen, welche Inhalte angezeigt werden. Die Bilder, die ACR liefert, wirken in vielerlei Hinsicht wie ein Fingerabdruck des Inhalts. Nach der Erfassung der "Fingerabdrücke" muss die Technologie jedoch feststellen, in welchem Netz oder auf welcher Plattform das Bild erschienen ist und wann es erschienen ist. Dazu muss die Technologie das Bild auf dem Bildschirm mit einem Bild abgleichen, das in einer vom Hersteller verwalteten Referenzbibliothek enthalten ist.
Es gibt drei mögliche Ergebnisse, wenn die Technologie versucht, diese Übereinstimmung herzustellen:
- Das Bild entspricht einem einzigen Eintrag in der Referenzbibliothek
- Das Bild stimmt mit mehreren Einträgen in der Referenzbibliothek überein
- Ein passendes Bild befindet sich nicht in der Referenzbibliothek
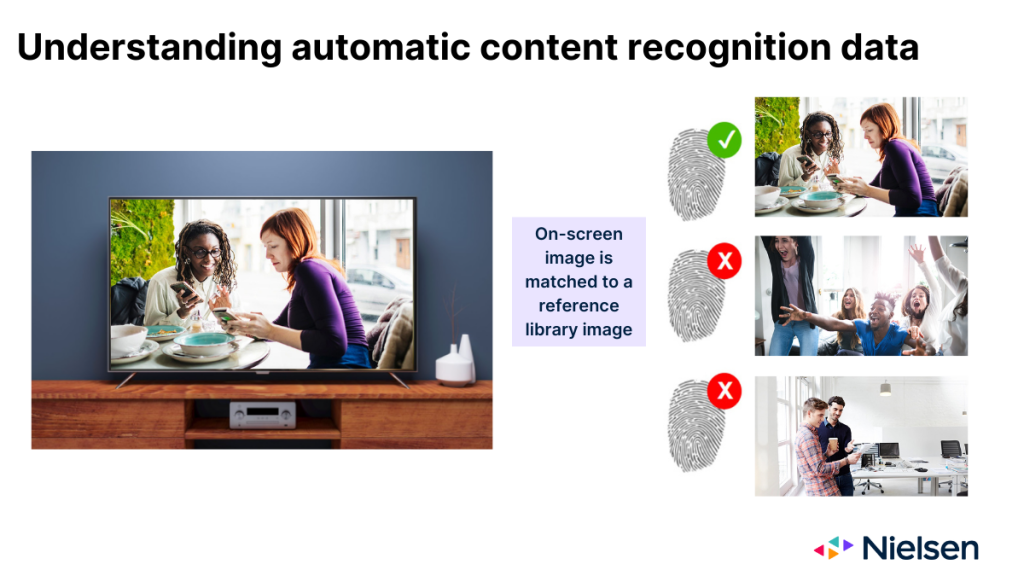
Für alle Beteiligten ist das erste Ergebnis das ideale Szenario. Das zweite Szenario ist weniger ideal und birgt ein gewisses Risiko von Fehlanrechnungen, einfach aufgrund der verschiedenen Gründe für die Mehrfachanrechnung (z. B. netzübergreifende Ausstrahlungen, Wiederholungen, Simulcasts). Im dritten Szenario erhält niemand eine Gutschrift, was natürlich das am wenigsten wünschenswerte Szenario ist. Der häufigste Grund für dieses Ergebnis ist, dass der Inhalt in einem Netzwerk ausgestrahlt wurde, das der OEM nicht überwacht.
Selbst wenn der Bildabgleich eine praktikable, eigenständige Messlösung wäre, wäre es niemals möglich, sie als solche zu nutzen. Wie Sie sich vorstellen können, sind die Kosten für die Pflege einer Bibliothek mit allen Einzelbildern eines jeden Ereignisses im Fernsehen nicht unerheblich. Es ist auch eine Aufgabe, die auf ewig exponentiell wachsen wird. Außerdem gibt es keine Standardaufbewahrungsfristen für Bilder.
Woher wissen wir also, dass die ACR-Technologie die richtige Wahl treffen wird? Ohne einen Mechanismus, der die Lücken füllen kann, wissen wir es nicht. Aus diesem Grund hat Nielsen in Wasserzeichen investiert, die weitaus deterministischer sind als Signaturen, sowie in Signatur-Backups für jeden gemessenen Feed. Dadurch werden alle Inhalte repräsentiert und die Lücken, die mit den Big Data verbunden sind, selbst geschlossen. Wenn diese Lücken geschlossen sind, bieten Big Data aus Quellen wie ACR den Vorteil der Skalierung in einer zunehmend segmentierten Medienlandschaft. Und wenn wir Gewichtungskontrollen verwenden, um Big Data mit Daten auf Personenebene zu kalibrieren, sind wir in der Lage, Vergleichspunkte zu sehen, die sonst leer bleiben würden.
In a recent study, Nielsen looked to understand the degree to which these reference library gaps affect ACR tuning logs—the basis for ACR-based measurement. In a September 2021 common homes analysis, we analyzed data from our two ACR provider partners to understand where reference library gaps might factor into measurement. In our study, we looked at both the concentration of viewing sources and the viewed minutes from the available sources.
Über alle Betrachtungsquellen hinweg haben wir festgestellt, dass unsere ACR-Anbieterpartner nur 31 % der verfügbaren Sender überwachen. Das bedeutet, dass sie für 69 % der Sender keine Daten in ihren Referenzbibliotheken vorhalten. Bei der Betrachtung der angesehenen Minuten haben wir festgestellt, dass 23 % der Minuten von Sendern stammen, die nicht überwacht werden. Das bedeutet, dass Unternehmen, die ausschließlich ACR-Daten für die Messung nutzen, die Impressionen auf Haushaltsebene um 23 % unterbewerten.
Trotz der Beschränkungen der ACR-Daten für sich genommen verstehen wir die Möglichkeit der Skalierung und Reichweite, die sie als zusätzliche Quelle für die Erfassung bieten - ähnlich wie die Rückkanal-Daten (RPD) von Set-Top-Boxen, die unsere Big-Data-Strategie ebenfalls mit panel kalibriert, um vergleichbare Beschränkungen zu beseitigen. Durch die Integration von Big-Data-Datensätzen mit unseren Fernsehdaten, die eine repräsentative Messung der gesamten USA ermöglichen, sind wir in der Lage, unsere Stichprobengröße erheblich zu erhöhen und gleichzeitig rigorose Data-Science-Methoden anzuwenden, um Lücken zu schließen und eine faire Repräsentation des gesamten US-Publikums über alle Netzwerke und Plattformen hinweg sicherzustellen.
A version of this article originally appeared on AdExchanger.



